



Master thesis : Sparse hypernetworks for multitasking

Cubélier, François 
Promotor(s) :
Geurts, Pierre
Date of defense : 27-Jun-2022/28-Jun-2022 • Permalink : http://hdl.handle.net/2268.2/14574
 All files (archive ZIP)
All files (archive ZIP) master_thesis_hypernetworks.pdf
master_thesis_hypernetworks.pdf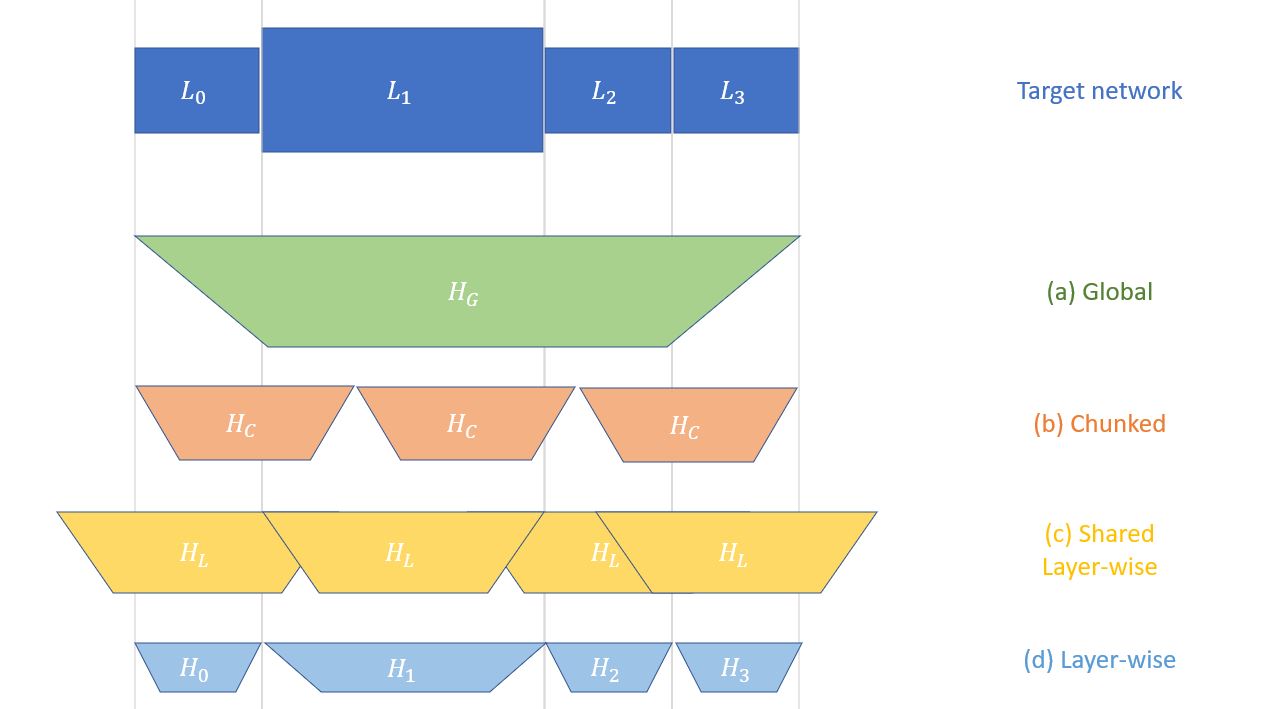 complete_hypernetwork_types.JPG
complete_hypernetwork_types.JPGDetails
| Title : | Master thesis : Sparse hypernetworks for multitasking |
| Author : | Cubélier, François
|
| Date of defense : | 27-Jun-2022/28-Jun-2022 |
| Advisor(s) : | Geurts, Pierre
|
| Committee's member(s) : | Wehenkel, Louis
Louveaux, Quentin
|
| Language : | English |
| Number of pages : | 73 |
| Keywords : | [en] deep learning [en] hypernetworks [en] multitasking [en] meta-models |
| Discipline(s) : | Engineering, computing & technology > Computer science |
| Target public : | Researchers Professionals of domain Student |
| Complementary URL : | https://github.com/francoisCub/multitasking-hnet |
| Institution(s) : | Université de Liège, Liège, Belgique |
| Degree: | Master en ingénieur civil en informatique, à finalité spécialisée en "intelligent systems" |
| Faculty: | Master thesis of the Faculté des Sciences appliquées |
Abstract
[en] Machine learning researchers have always been interested in creating less narrow artificial intelligence. Meta-models, i.e. models capable of producing other models, could potentially be a key ingredient for building new highly multitasking capable models. Hypernetworks, which are neural networks that produce the parameters of other neural networks, can be used as meta-models. However, due to the large number of parameters in neural networks nowadays, it is not trivial to build hypernetworks with the large output size required to produce all the parameters of another neural network. Current solutions, like chunked hypernetworks, which split the target parameter space into parts and reuse the same model to produce each part, achieve good results in practice and are scalable independently of the maximal size of the layers in the target model. However, they seem unsatisfactory because they arbitrarily split the target model parameters into chunks. In this work, we propose a new scalable architecture for building hypernetworks, which consists in a sparse MLP with hidden layers of exponentially growing size. After testing different variations of this architecture, we compare it with chunked hypernetworks on multitasking computer vision benchmarks. We show that they can match the performance of chunked hypernetworks, even though they were slightly behind on more complex problems. We also show that linear sparse hypernetworks outperformed their non-linear version and chunked hypernetworks for inferring new models for new tasks with a pretrained task-conditioned hypernetwork. This is may indicate that linear sparse hypernetworks have better generalization properties than more complex hypernetworks. In addition to proposing this sparse architecture and as a preamble of this work, we also review the literature on hypernetworks and propose a typology of hypernetworks. Even though the results obtained are promising, there are still many ways to improve sparse hypernetworks and, more generally, hypernetworks that can be explored in future research.
File(s)
Document(s)

Annexe(s)

Cite this master thesis
The University of Liège does not guarantee the scientific quality of these students' works or the accuracy of all the information they contain.
